1. ROUTAGE AVANCE ET CONTROLE DE TRAFIC SOUS LINUX
Nous nous attacherons dans ce chapitre à expliquer quelles sont les nouvelles fonctionnalités de routage et filtrage que propose le noyau 2.4 de Linux, à savoir :
Au cours de ce projet, nous n’avons étudié que les six premiers aspects qu’offre le routage avancé.
1.2.1 Configuration des interfaces
1.2.2 Gestion des adresses de protocole
1.2.3 Gestion des tables de routage
1.2.4 Gestion de la table des règles de routage
1.2.5 Gestion des table arp
1.2.6 Autres fonctionnalités
1.3 Gestion de mise en file d'attente pour l'administration de la bande passante
1.3.1 Quelques définitions
1.3.2 Principe de fonctionnemement
1.3.3 Gestionnaire de mise en file d'attente simple, sans classe
1.3.4 Gestionnaire de mise en file d'attente basée sur les classes
1.3.5 Filtres avancés pour la classification des paquets
1.1 CONFIGURATION DU NOYAU
Tout d’abord, il est important de compiler le noyau en autorisant les options d’administration réseau. Nous ne décrirons pas ici les étapes de la compilation et de l’installation du noyau. Voici un aperçu des options qui ont été validées, contenues dans le fichier .config :
| . . . # CONFIG_PACKET=m
CONFIG_IP_NF_CONNTRACK=y
CONFIG_NET_SCHED=y CONFIG_NET_CLS_TCINDEX=y CONFIG_NET_CLS_ROUTE4=y CONFIG_NET_CLS_ROUTE=y CONFIG_NET_CLS_FW=y CONFIG_NET_CLS_U32=y CONFIG_NET_CLS_RSVP=y CONFIG_NET_CLS_RSVP6=y CONFIG_NET_CLS_POLICE=y . |
Figure 1 : Fichier .config
Pour plus de renseignements, consulter le Kernel HOWTO.
1.2 LA COMMANDE IPROUTE 2
La commande iproute2 remplace les commandes
arp, ifconfig et route
pour les versions de noyau Linux des séries 2.2 et plus. En effet, elle
permet de gérer des fonctionnalités qui n’étaient
pas prises en charge auparavant, par exemple, la gestion des tunnels GRE.
1.2.1 Configuration des interfaces
Une des fonctionnalités que nous apporte iproute2 est la configuration des interfaces, c'est-à-dire de nos liens, avec ip link.
Sur notre routeur, les interfaces sont eth0 (ethernet) et lo (loopback), eth0 est en fait notre lien avec l’extérieur, c'est-à-dire le lien avec les autres ordinateurs. Tout paquet passant par le routeur et se dirigeant vers un ordinateur du réseau sort par cette interface. Une interface possède un identifiant matériel qui est une adresse physique ou adresse MAC. On lui ajoute ensuite une adresse de protocole qui est l’adresse IP de notre machine. Dans notre cas, eth0 a pour adresse IP 192.168.0.2. La boucle de retour lo a pour adresse 127.0.0.1 et correspond à notre propre ordinateur.
Les commandes correspondantes à ip link
nous permettent de voir ou même de changer l’état de ces
interfaces.
1.2.2 Gestion des adresses de protocole
Comme nous l’avons vu précédemment, une interface possède une adresse MAC, ces adresses sont gérées par les commandes de ip address. En effet, ip address permet de voir les adresses et leurs propriétés, ainsi que d’en ajouter de nouvelles et de supprimer les anciennes.
Pour créer notre réseau,
il a fallu faire un réseau virtuel, et c’est
avec la gestion des adresses de protocole que nous avons pu configurer l’interface
eth0 pour qu’elle puisse gérer deux réseaux. Nous avons
donc, grâce à ip address, défini l’interface eth0:0
en lui attribuant l’adresse 192.168.1.2. Eth0 possède, désormais,
deux adresses, une pour les liens vers le réseau 192.168.0.0 et l’autre
pour le réseau 192.168.1.0.
1.2.3 Gestion des tables de routage
La gestion des tables de routage se fait avec la commande ip route, qui permet de voir nos routes, de les modifier ou d’ajouter un nouveau chemin. Une route est le chemin par où passe un paquet sortant de notre machine, en fonction de sa destination. Elle nous indique le nom et l’adresse de l’interface par où devra sortir le paquet.
Dans notre configuration, nous avons besoin que les paquets à destination du réseau 192.168.0.0 sortent par l’interface eth0 d’adresse ip 192.168.0.2, et que ceux allant au réseau 192.168.1.0 passe par l’interface eth0 :0 d’adresse 192.168.1.2. La table de routage de notre routeur devra donc être la suivante :
| Table de routage IP du noyau Destination Passerelle Genmask Indic ... Iface 192.168.1.0 0.0.0.0 255.255.255.0 U eth0 192.168.0.0 192.168.0.2 255.255.255.0 UG eth0 192.168.0.0 0.0.0.0 255.255.255.0 U eth0 127.0.0.0 0.0.0.0 255.0.0.0 U lo 0.0.0.0 192.168.0.1 0.0.0.0 UG eth0 |
Figure 2 : Table de routage du routeur Linux
1.2.4 Gestion de la table des règles de routage
Les algorithmes classiques d’acheminement utilisés dans Internet prennent des décisions d’acheminement basées seulement sur l'adresse de destination des paquets. Avec iproute2 nous pouvons acheminer les paquets non seulement en fonctions de l’adresse de destination, mais aussi en fonction de l’adresse source, du protocole, des ports utilisés... Tout ceci est géré par la commande ip rule, qui permet d’insérer une nouvelle règle de routage ou de l’effacer.
Quand le noyau doit prendre une décision de routage, il
recherche quelle table consulter. Il y a par défaut trois tables qui
sont : main, local et default. Au départ, toutes les règles de
routage sont appliquées à tous les paquets. Avec ip
rule nous pouvons définir nos propre règles et définir
si telle ou telle machine du réseau est plus prioritaire que les autres.
1.2.5 Gestion des tables arp
ARP est le protocole de résolution d’adresse (Address Resolution Protocol). Une machine est identifiée, dans le domaine Internet, par son adresse IP. Une adresse IP, cependant, n’indique pas la localisation physique de la machine. Elle possède aussi une adresse physique utilisée par le protocole d’accès réseau. Chaque carte Ethernet est identifiée par une adresse physique. Ainsi, deux équipements sur le réseau Ethernet ne peuvent communiquer que s’ils connaissent leurs adresses physiques mutuelles. C’est ici que le protocole ARP entre en jeu. Il permet d’obtenir l’adresse Ethernet d’un équipement dont on connaît l’adresse IP.
Chaque ordinateur possède une table ARP où sont
indiquées l’adresse IP et l’adresse physique des machines
du réseau. On peut consulter et modifier le cache (table) arp (neighbor)
avec la commande ip neighbour.
1.2.6 Autres fonctionnalités
Il existe d’autres fonctionnalités de la commande iproute2 que nous n’allons pas détailler mais que nous allons expliquer brièvement dans cette partie.
Il y a comme autres fonctionnalités, la gestion des adresses
multidistribution avec ip maddress, du routage multidistribution
avec ip mroute, la configuration de tunnel avec ip
tunnel et la surveillance d’état avec ip
monitor.
Une adresse multidistribution (multicast) est une adresse qui possède
plusieurs utilisateurs. Iproute2 peut aussi surveiller
l'état des interfaces, des adresses et des routes sans interruption,
avec ip monitor.
1.3 GESTION DE MISE EN FILE D’ATTENTE POUR L’ADMINISTRATION DE LA BANDE PASSANTE
La mise en file d’attente est un processus qui permet de déterminer la manière dont les données sont envoyées, et par là même, de mettre en forme le trafic. Par exemple, on peut décider d’envoyer tel flux de données (ftp) dans une file d’attente de priorité plus importante que celle de la file d’attente dédiée au trafic habituel (le reste). Avant de poursuivre plus en avant sur les principes d’administration de la bande passante, il est nécessaire de rappeler quelques définitions.
On appelle gestionnaire de mise en file d’attente (queueing discipline ou qdisc) un algorithme qui gère la file d’attente d’un périphérique, soit pour les données entrantes (ingress), soit pour les données sortantes (egress). On distingue deux types de gestionnaires : les gestionnaires sans classe et ceux basés sur les classes.
Un gestionnaire de mise en file d’attente sans classe (classless qdisc) est un gestionnaire de mise en file d’attente qui n’a pas de subdivisions internes configurables.
Un gestionnaire de mise en file d’attente basée sur des classes contient de multiples classes. Chacune de ces classes contient un gestionnaire de mise en file d’attente supplémentaire, qui n’est pas obligatoirement basé sur des classes. Nous en verrons des exemples dans le paragraphe 1.3.4.
Un gestionnaire de mise en file d’attente peut avoir beaucoup de classes, chacune d’elles étant internes au gestionnaire. Chacune de ces classes peut contenir un gestionnaire de mise en file d’attente réel.
Les classificateurs (classifiers) permettent aux gestionnaires de mise en file d’attente basée sur des classes de déterminer vers quelles classes ils doivent envoyer leurs paquets.
Cette classification peut être utilisée en utilisant des filtres (filters). Un filtre est composé d’un certain nombre de conditions qui, si elles sont toutes vérifiées, satisfait le filtre.
1.3.2 Principe de fonctionnement
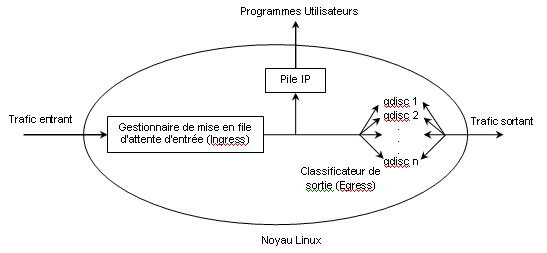
Maintenant que nous avons vu ce que sont les gestionnaires de file d’attente, expliquons le mécanisme qui les régit à l’aide de la figure ci-dessous :
Figure 3 : Gestion de mise en file d’attente pour l’administration de la bande passante
Le trafic du réseau qui entre dans le routeur passe dans le gestionnaire de mise en file d’attente d’entrée ingress qui peut appliquer des filtres à un paquet et décider, le cas échéant, de le supprimer.
Si le paquet est autorisé à continuer, il peut être destiné à une application locale. Il entrera alors dans la couche IP pour être traité et délivré à un programme utilisateur. Le paquet peut être également transmis sans entrer dans une application. Il sera alors destiné au classificateur de sortie egress. Les programmes utilisateurs peuvent délivrer des données qui seront alors transmises et examinées par Egress.
Au niveau du classificateur, le paquet est examiné et mis en file d’attente vers un certain nombre de gestionnaires de mise en file d’attente (qdisc 1, qdisc2, …, qdisc i, …, qdisc n). Par défaut, il n’y a qu’un seul gestionnaire egress installé, pfifo_fast, qui reçoit tous les paquets. C’est ce qu’on appelle la mise en file d’attente (enqueuing).
Le paquet réside maintenant dans le gestionnaire de mise en file d’attente et attend que le noyau le réclame pour le transmettre à travers l’interface réseau. Le fait de retirer le paquet de la file d’attente est encore appelé dequeueing.
Le schéma de la figure 3 montre le cas où il n’y
a qu’un seul adaptateur réseau, ce qui correspond à notre
configuration. Chaque adaptateur réseau a un gestionnaire d’entrée
et de sortie.
1.3.3 Gestionnaires de mise en file d’attente simple, sans classe
Les gestionnaires de mise en file d’attente sans classe sont ceux qui acceptent les données et ne font que les réordonnancer, les retarder ou les jeter. Ils peuvent être utilisés pour mettre en forme le trafic d’une interface, sans aucune subdivision.
Le gestionnaire le plus souvent utilisé est celui par défaut, pfifo_fast. Il s’agit d’une file de type « first in, first out » c'est-à-dire « premier entré, premier sorti ». Les paquets ne subissent donc pas de traitements spéciaux. En réalité, la file d’attente possède trois « bandes ». Chaque bande suit la règle FIFO. La bande i+1 ne peut être traitée tant qu’un paquet réside encore dans la file d’attente de la bande i. Cela revient à dire que la bande 0 est plus prioritaire que la bande 1, elle-même plus prioritaire que la bande 2. La mise en file d’attente des paquets dans la bande 0, 1 ou 2 dépend de la valeur du champ TOS (Type Of Service) contenue dans l’entête de ces paquets IP. Des explications plus détaillées sont fournies en section 6.
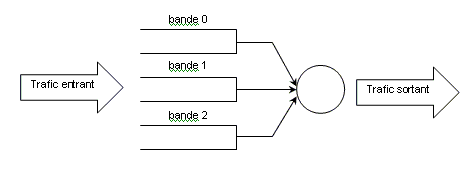
Figure 4 : File d’attente pfifo_fast
Un autre gestionnaire de mise en file d’attente simple est le Token
Bucket Filter(filtre à seau de jetons), ou TBF.
Celui-ci se contente de laisser passer les paquets entrants avec un débit
n’excédant pas une limite que l’on doit fixer, tout en laissant
la possibilité d’envoyer de courtes rafales de données (bursts)
avec un débit dépassant cette limite. Le principal avantage du
TBF est qu’il est très précis et peu gourmand du point de
vue réseau et processeur. Il est à utiliser pour ralentir
une interface.
Un troisième type de gestionnaire de mise en file d’attente
simple est le Stochastic Fairness Queueing
SFQ, ou mise en file d’attente stochastiquement équitable.
Le SFQ est basé sur un algorithme qui divise le trafic à travers
un nombre limité de files d’attente de type FIFO en utilisant un
algorithme de hachage. Cela revient à allouer à pratiquement chaque
flux une file d’attente FIFO. Il est donc utilisé en cas de saturation
de l’interface de sortie et il permet de s’assurer
qu’aucune session n’accapare la bande passante vers l’extérieur.
1.3.4 Gestionnaires de mise en file d’attente basée sur les classes
Les gestionnaires de mise en file d’attente basée sur les classes sont utilisés lorsqu’il y a différentes sortes de trafic qui doivent être traités de manière différente.
Quand le trafic entre dans ce type de gestionnaire, il doit être envoyé vers l’une de ses classes : il doit être « classifié ». Pour déterminer vers quelle classe diriger un paquet, on fait appel à des filtres. Les filtres attachés au gestionnaire retournent alors une décision qui sera utilisée pour mettre en file d’attente le paquet dans l’une des classes. Chaque sous-classe peut essayer d’autres filtres pour voir si de nouvelles instructions s’appliquent. Si ce n’est pas le cas, la classe met le paquet en file d’attente dans le gestionnaire de mise en file d’attente qu’elle contient.
Chaque interface à un gestionnaire de mise en file d’attente racine de sortie (egress root qdisc) qui est par défaut pfifo_fast. Tout gestionnaire est repéré par un descripteur, ou handle. Ces descripteurs sont constitués de deux parties : un nombre majeur et un nombre mineur. Le gestionnaire racine est habituellement nommé 1 :, ce qui est équivalent à 1 :0. Le nombre mineur d’un gestionnaire de mise en file d’attente est toujours 0. Les classes doivent avoir le même nombre majeur que leur parent. Un exemple de hiérarchie typique de classes est illustré par la figure qui suit :
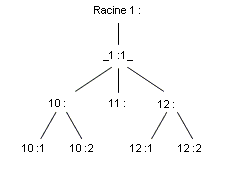
Figure 5 : Hiérarchie de classes
Lorsque le noyau décide qu’il doit extraire des paquets pour les envoyer vers l’interface, le gestionnaire racine 1 : reçoit une requête de « dequeue » qui est transmise à 1 :1, qui à son tour l’envoie à 10 :, 11 : et 12 :. Chaque gestionnaire interroge ses descendances qui essaient de retirer de leur file d’attente les paquets. Par exemple, si seule la file 10 :1 contient un paquet, alors le noyau doit parcourir l’ensemble de l’arbre.
Les sous-classes ne parlent qu’à leur gestionnaire de mise en file d’attente parent, jamais à l’interface. Seul le gestionnaire racine a sa file d’attente vidée directement par le noyau. Par conséquent, les classes ne peuvent jamais retirer des paquets de leur file d’attente plus rapidement que leur parent n’autorise.
On distingue trois types de gestionnaire de mise en file d’attente basée sur les classes : PRIO, Class Based Queueing (CBQ) et Hierarchical Token Bucket (HTB.), ou seau à jetons hiérarchique.
Le gestionnaire PRIO est un gestionnaire qui délivre toujours un paquet s’il y en a un de disponible. Il ne retarde donc jamais un paquet si l’adaptateur réseau est prêt à l’envoyer. Il ne met pas vraiment en forme le trafic, il se contente de le subdiviser en se basant sur la manière dont les filtres ont été configurés. Quand un paquet est mis en file d’attente, une classe est choisie en fonction de ces filtres. Par défaut, il existe trois classes contenant chacune par défaut des gestionnaires de mise en file d’attente FIFO sans structure interne qui peuvent être remplacés par n’importe quel autre gestionnaire, par exemple, SFQ.
Le gestionnaire de mise en file d’attente basée sur les classes le plus connu et le plus usité est le Class Based Queueing ou CBQ. Il s’agit également là du gestionnaire le plus complexe et qui a l’inconvénient de ne pas être très précis. En effet, le CBQ fonctionne en s’assurant que le lien est inactif juste assez longtemps pour abaisser la bande passante réelle au débit configuré. Par exemple, si l’on souhaite mettre en forme une connexion de 10 Mbits/s à 1 Mbits/s, le lien doit être inactif 90 % du temps. Si ce n’est pas le cas, on doit limiter le taux de sorte à ce qu’il soit inactif 90 % du temps. CBQ permet la mise en forme du trafic et obtient de bons résultats dans de nombreux cas de figure.
Le troisième type de gestionnaire de mise en file d’attente
basée sur les classes est le seau à jetons hiérarchique,
ou Hierarchical Token Bucket
(HTB). L’approche hiérarchique est bien
adaptée pour les cas de configuration où il y a une largeur
de bande passante fixée à diviser entre différents éléments.
Chacun de ces éléments aura une bande passante garantie, avec
la possibilité de spécifier combien de bande passante pourra être
empruntée. HTB travaille comme CBQ mais il ne recourt pas à des
calculs de temps d’inoccupation pour la mise en forme du trafic. A la
place, il fait appel à un Token Bucket Filter basé sur des classes.
1.3.5 Filtres avancés pour la classification des paquets
Pour déterminer quelle classe traitera un paquet, la « chaîne de classificateurs » est appelée chaque fois qu’un choix a besoin d’être fait. Cette chaîne est constituée de tous les filtres attachés aux gestionnaires de mise en file d’attente basée sur des classes qui doivent prendre une décision.
Parmi tous les classificateurs qui existent, on peut citer :
Le classificateur que nous avons étudié est le classificateur u32 car il s’agit du filtre le plus avancé dans l’implémentation courante. Il permet de filtrer les paquets en fonction de la valeur de n’importe quel champ contenu dans le paquet. Par exemple, la prise de décision peut s’effectuer en fonction de la valeur du champ TOS, ou encore selon la valeur du port destination TCP.